This is the second instalment of a “Scaling Agile” blog series. The first instalment was “Scaling Agile: A Law And Two Paradoxes”. Before proceeding further, please, read it, as it sets the context for what follows.
In this post I’ll suggest a way to find an answer to this question:
Q1: How many people and teams can be added to the project to deliver more features in less time?
In other terms, how can the throughput of delivered features be increased? This isn’t always the right question to answer (almost never is) as focusing on throughput of deliverables is not the same as focusing on value delivered to the customers, but, in the following, I’ll make some simplifying assumptions and show that, also in ideal scenarios, there are some hard limits to how much a project can scale up. In particular, I’ll assume that the project meets all prerequisites for scaling (described in “Scaling Agile: A Law And Two Paradoxes”), which, among other things mean:
- Requirements are subject to ruthless prioritisation—i.e., non-essential, low value features are aggressively de-prioritised or binned. In this scenario there is a clear positive relationship between features and value delivered
- All teams currently in the project are working at peak effectiveness and efficiency—i.e., the existing teams are already as good as they can be, and they might (but not necessarily will) be able to do more only by increasing their size or their number
- There are effective metrics in place to measure, among others, productivity, quality, and throughput
Being able to answer Q1 is important as “deliver more faster” seems to be the main reason for scaling up in most large software projects. As it happens, some time ago, I was hired as a consultant in a very large scale agile project precisely to answer that question.
The very first thing I did was to survey the literature to find if anybody had already answered Q1. In the process, I discovered that the scaled agile literature has quite a bit of information about the pros and cons of component vs feature teams, but—despite this being a very obvious and important issue in the context of scaling—I couldn’t find much information that would help in answering it.
Looking further, I read again Fred Brooks’s “Mythical Man Month” book, and came across this quote (highlights mine):
“The number of months of a project depends upon its sequential constraints. The maximum number of men depends upon the number of independent subtasks. From these two quantities one can derive schedules using fewer men and more months. (The only risk is product obsolescence.) One cannot, however, get workable schedules using more men and fewer months.”
If you haven’t recognised it yet, that is Amdahl’s Law applied to teams. That made perfect sense to me. Here are a couple of important implications:
- The total time spent in sequential activities—anything that has to be done by one team at the time but affects most or all other teams, e.g., the creation of a common component or library, setting up some common infrastructure for testing and CI, etc.—is a lower bound for the time necessary to deliver the required functionality. The project cannot go faster than that
- The maximum number of independent sub-projects, in which the main project can be split, is an upper bound to the maximum number of teams that can be added productively to the project. Note that “independent” in this context is a relative concept—sub-projects of a big project always have some dependencies among them, and “independent” ones have just a few
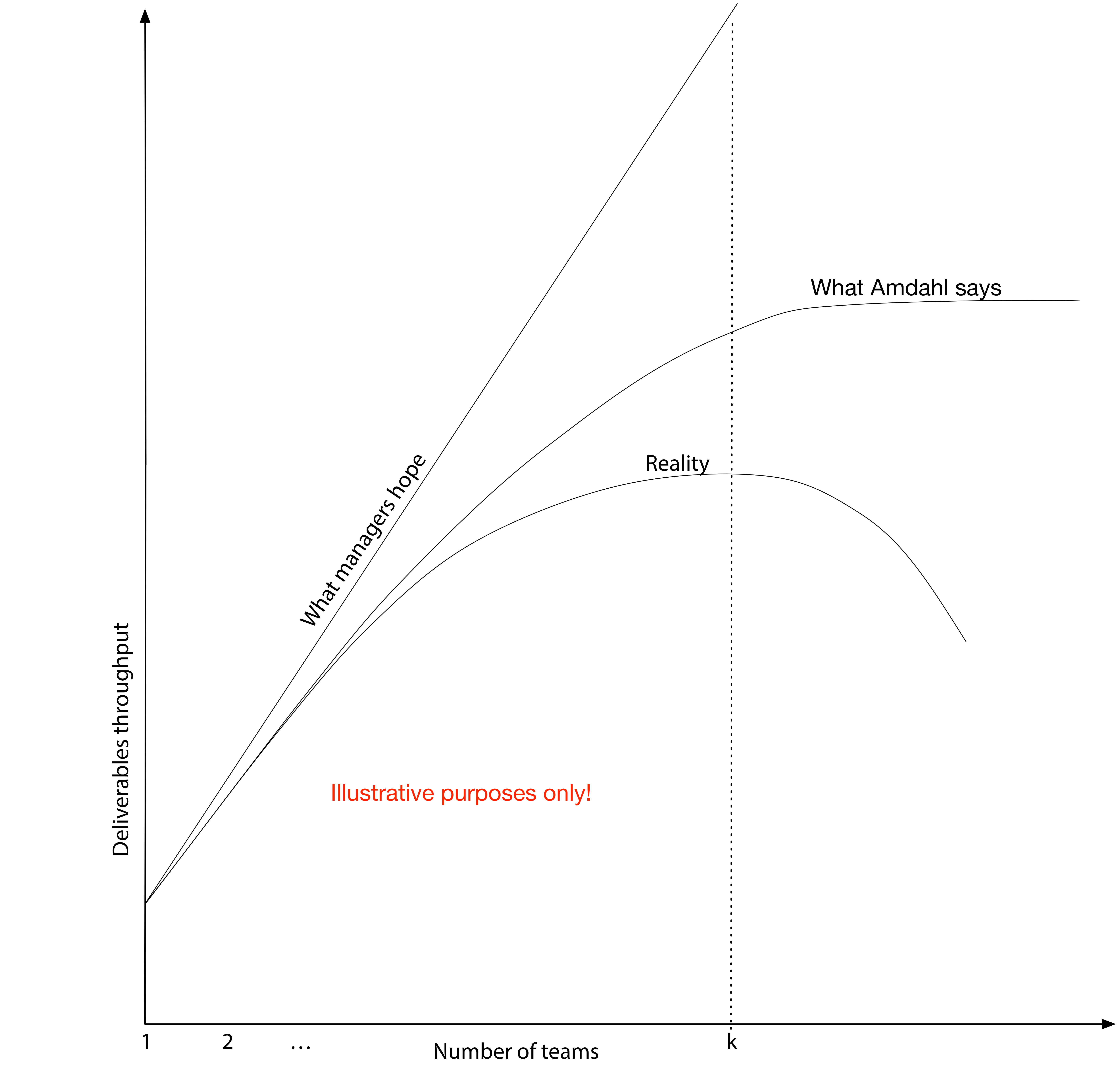
The picture below (which is meant to be descriptive, not mathematically accurate) shows what can be achieved in practice—as you can see, it’s far less than the theoretical limits discussed above:
- The straight line labelled “What managers hope” describes the typical attitude I’ve seen in many projects: managers add teams expecting to achieve linear scalability for throughput
- The line labelled “What Amdahl says” describes the upper bound given by Amdhal’s Law, which tends asymptotically to a finite maximum value for throughput (remember the amount of sequential activities? That’s why there is the asymptotic value), therefore, even in the scenario in which the teams were completely independent from each other, after a certain point adding new teams would be pointless
- The line labelled “Reality” describes what happens in reality. The throughput will increase much less than the theoretically predicted level, and will peak when the number of teams reaches a maximum k. That’s the point where communication and synchronisation issues start to become the predominant factors affecting throughput. Any more teams than that and the overall throughput for the project will go down. If you ever worked in projects with more than a (very) few teams chances are you’ve seen this happening first hand
There are three important things to notice.
The first is that the cost per deliverable will increase (or, equivalently, productivity will decrease) more than linearly with the number of people involved, and it may become unacceptable well before scaling to k teams.
The second is that the shape of the “Reality” curve above is independent on the type of teams—component or feature, or any mix of the two—and it will always below Amdahl’s curve.
The third is that, independently of any methodology or process used (agile or otherwise), the curves for the throughput will always resemble the ones above. In other terms, those relationships are more fundamental than the methodologies used and cannot be eliminated or avoided.
Now, suppose cost is not a problem, and that time to market is more important. To answer Q1 we can either try to calculate the value of k in some analytical way (which I don’t know how to do, or if it is even possible in some contexts), or we can do something else—i.e., add people, measure the effects, and act accordingly. The second approach is the one I suggested to my client. Specifically:
- When increasing the size of an existing team do the following:
- Check with the teams involved if they need help—they might already be working at peak throughput, with everybody busy, but not overloaded, in which case they are better left alone
- If increasing the size of the team is a viable proposition, do it incrementally by adding a few people at a time. Measure the effects (using the metrics you’ve got already in place). There may be a small throughput drop in the short term, but then throughput should increase again after not too long (e.g., a couple of sprints if using Scrum). If it doesn’t, or if quality suffers, understand the reasons and, if necessary, revert the decision remove the new members from the team
- When adding a new team to the project do the following:
- Ensure that the scope of work is well understood and is sufficiently self-contained with minimal and clear dependencies on other teams
- Start small. 3-4 people maximum with the required skills—including knowledge of the technologies to be used, and of the domain
- The Product Owner for the new team is identified and available
- The team is given all the necessary resources to perform their job—e.g., software, hardware, office space, etc.
- There is an architect available to help the team proceed in the right directions according to the reference architecture of system
- Measure the effects. There may be a small decrease in throughput in the short term, but then it should increase again after not too long (e.g, a couple of sprints if using Scrum). If it doesn’t, or if quality suffers, understand the reasons and, if necessary, revert the decision and remove the team from the project
As you can see, adding people might, in some circumstances, make the project faster, but there are some hard limits to the number of people and teams that can be added, and the costs will increase more (usually much more) than linearly with the number of people—even in an almost ideal situation. As my friend Allan Kelly says: “Software has diseconomies of scale – not economies of scale”.
If you, despite all the dangers, decide to scale up your project, and try to do so applying the recommendations above, I would love to hear your feedback about how it worked out.
The next instalment of this series will be about component teams vs feature teams.





